# Аналіз предметної області
# Вступ
Система аналізу медіа-контенту є ключовим інструментом у сучасному інформаційному суспільстві, де цифрові дані стрімко зростають. Вона дозволяє структурувати різні типи контенту, глибше розуміти його значення та вплив на аудиторію, виявляти тренди й аналізувати громадську думку. У цьому документі подано огляд основних визначень, пов'язаних із медіа-контентом. Розглянуто різні підходи до вирішення завдань аналізу контенту та проведено порівняльний аналіз існуючих рішень. Особливу увагу приділено необхідності розробки нових інформаційних систем, що поєднують універсальність, сучасні технології та ефективність обробки великих обсягів даних для підвищення точності та релевантності аналізу.
# Зміст
- Основні визначення
- Підходи та способи вирішення завдання
- Порівняльна характеристика існуючих засобів вирішення завдання
- Висновки
- Посилання
# Основні визначення
Медіа-контент [1] – це змістовно значуще наповнення цифрових ресурсів, що інтегрує різну за формою подання та кодування інформацію (текстову, графічну, аудіовізуальну тощо), орієнтовану на задоволення соціальних, інформаційних та емоційних потреб людини. Отже, медіаконтент є одним із основних видів представлення інформації та комунікації в сучасній культурі, освіті, політиці, економіці тощо.
Обробка природної мови (NLP) [2] – це вивчення та застосування методів та інструментів, які дозволяють комп’ютерам обробляти, аналізувати, інтерпретувати та міркувати про людську мову. NLP є міждисциплінарною сферою, яка поєднує в собі методи, розроблені в таких галузях, як лінгвістика та інформатика.
Інтелектуальний аналіз тексту (Text mining) [3] - напрям інтелектуального аналізу даних (англ. Data Mining) та штучного інтелекту, метою якого є отримання інформації з колекцій текстових документів, ґрунтуючись на застосуванні ефективних, у практичному плані, методів машинного навчання та обробки природної мови. Інтелектуальний аналіз тексту використовує всі ті ж підходи до перероблювання інформації, що й інтелектуальний аналіз даних, однак різниця між цими напрямками проявляється лише в кінцевих методах, а також у тому, що інтелектуальний аналіз даних має справу зі сховищами та базами даних, а не електронними бібліотеками та корпусами текстів.
Токенізація [4] - це процес розбиття фрагмента тексту на менші одиниці, що називаються токенами, які можуть бути словами, фразами, символами або іншими значущими елементами, для полегшення подальшого аналізу та обробки в процесі обробки природної мови (NLP) та аналізу тексту.
Big Data (Великі дані) [5] – це великий масив структурованої та неструктурованої інформації, а також інструменти, підходи, методи обробки та зберігання даних.
Метадані [6] – це засіб класифікації, упорядкування та характеристики даних. Тобто, метадані — це дані про дані (про їх склад, зміст, статус, походження, місцезнаходження, якість, формати, обсяг, умови доступу, авторські права тощо).
Інформаційний шум [7] – неважлива, вторинна інформація, якою супроводжується або заміщується основне повідомлення.
Моніторинг [8] – це систематичне відстеження якісних і кількісних показників, які характеризують якусь діяльність та/або поточну ситуацію. Головна мета моніторингу — «знімати показники» стану об'єкта спостереження і виявляти розбіжності з плановими (або виявляти тенденції розвитку й передбачати майбутні стани).
API [9] – це набір інструкцій, які дозволяють різним програмам спілкуватись між собою та обмінюватись даними.
Семантичний аналіз [10] – це процес визначення смислу та інтерпретації значення слів та фраз у контексті, в якому вони вживаються. Основна мета семантичного аналізу тексту полягає в тому, щоб зрозуміти, що автор намагається передати та який вплив він має на читачів.
# Підходи та способи вирішення завдання
Для розробки ефективної системи аналізу медіа-контенту, необхідно використовувати різноманітні підходи та методики, що дозволяють аналізувати і інтерпретувати великі обсяги даних з різних точок зору. Нижче розглянуто основні підходи та шляхи вирішення проблеми аналізу медіа-контенту.
# 1. Традиційні методи контент-аналізу
# 1.1. Ручний контент-аналіз
Ручний контент-аналіз передбачає безпосередню участь дослідника у процесі аналізу тексту. Цей метод дозволяє глибше зрозуміти контекст та зміст тексту, виявляти теми, мотиви та інтерпретувати їх значення. Проте, ручний аналіз є трудомістким і потребує багато часу.
# 1.2. Методи якісного аналізу
До методів якісного аналізу належать:
- Традиційний аналіз: дослідники розглядають тексти у контексті їх створення, мотивації авторів та очікуваного впливу на аудиторію.
- Феноменологічний аналіз: ідентифікація суб'єктивного досвіду та особистісних смислів.
- Аналіз дискурсу: вивчення конструктивного характеру мови і соціальної реальності.
- Аналіз медійних рамок: вивчення того, як медіа представляють інформацію та впливають на сприйняття аудиторією.
- Етнографічний аналіз: глибокі дослідження медіа-контенту у контексті конкретної культури або групи людей.
- Емпіричний аналіз інтерфейсів і дизайну: дослідження впливу дизайну на взаємодію користувача з контентом.
- Символьний аналіз: дослідження використання символів у медійних текстах для розкриття їх значення.
# 2. Кількісні методи контент-аналізу
# 2.1. Обробка природної мови (NLP)
NLP (Natural Language Processing) включає методи та інструменти для автоматичного аналізу тексту. Це дозволяє обробляти великі обсяги даних і виявляти ключові слова, фрази та тенденції. Основні завдання NLP включають видобування даних, розпізнавання мови, машинний переклад, інформаційний пошук та інші.
Natural Language Processing [2]
# 2.2. Інтелектуальний аналіз тексту
Інтелектуальний аналіз тексту використовує методи машинного навчання для аналізу великих обсягів текстових даних. Це включає категоризацію, кластеризацію, вилучення концептів, розробку таксономій, узагальнення документів та аналіз настроїв.

Text mining [11]
# 2.3. Статистичний аналіз
Статистичний аналіз використовує математичні моделі для вивчення залежностей, кореляцій та регресій у медіа-дослідженнях. Це допомагає виявляти статистично значущі закономірності у медіа-контенті.
# 2.4. Аналіз часових рядів
Аналіз часових рядів дозволяє досліджувати динаміку зміни медіа-контенту у часі. Це допомагає виявляти, які теми або тренди змінюються з плином часу, та як це впливає на аудиторію.
# 2.5. Токенізація
Токенізація - це процес розбиття тексту на окремі "токени" або одиниці, які можуть бути словами, фразами або реченнями. Це допомагає перетворити текст в структуровану форму для подальшого аналізу.
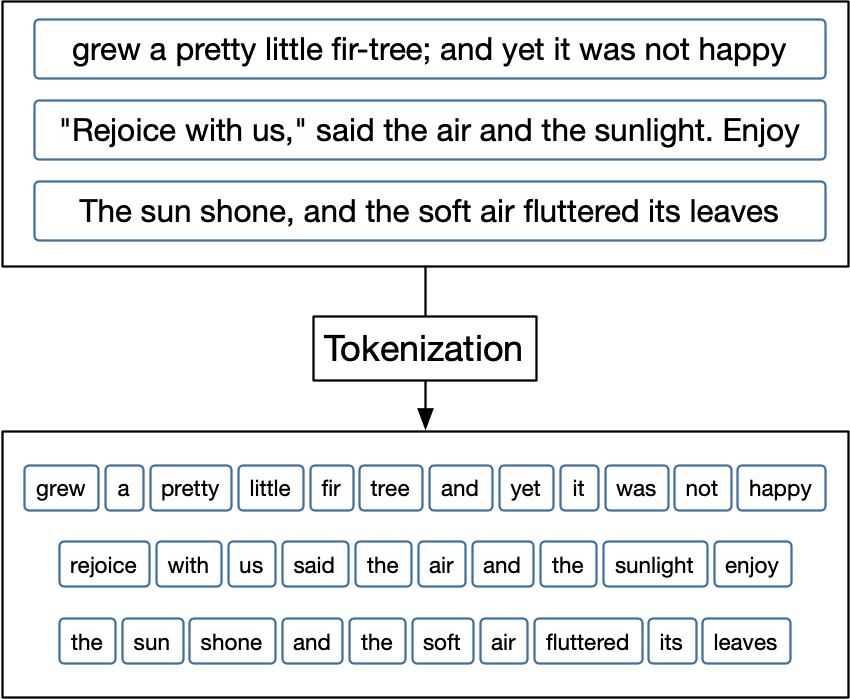
Tokenization [12]
# 2.6. Аналіз синтаксичних структур
Аналіз синтаксичних структур дозволяє визначити відношення між словами у тексті та зрозуміти структуру речень. Це допомагає більш точно аналізувати зміст тексту.
# 3. Комбіновані підходи
Комбіновані підходи у медіа-аналітиці — це методи, що поєднують якісні та кількісні техніки, дозволяючи отримати всебічне уявлення про контент, що досліджується. Якісні методи забезпечують глибокий аналіз змісту та контексту, допомагаючи зрозуміти приховані значення, символи та культурні коди, тоді як кількісні методи надають можливість обробляти великі обсяги даних і робити статистично обґрунтовані висновки.

Combined approaches [13]
Наприклад, кількісні підходи дозволяють визначити частоту згадування певних тем або понять у різних медіа, що дає змогу оцінити їх популярність або суспільний резонанс. У той же час, якісний аналіз допомагає зрозуміти, як саме ці теми представлені: з позитивним чи негативним акцентом, які наративи використовуються, які цінності та ідеї підкреслюються. Такий комбінований підхід дозволяє побачити повну картину, що значно покращує розуміння явища і робить аналітику медіа більш точною та інформативною.
# 4. Використання сучасних технологій
Сучасні технології займають ключову роль у медіа-аналітиці, адже обробка величезних обсягів даних вручну стала практично неможливою. Використання технологічних рішень дозволяє аналізувати контент більш ефективно, швидше і з меншими витратами ресурсів. Основні напрями, де сучасні технології застосовуються для аналізу медіа-контенту, включають машинне навчання, штучний інтелект та роботу з великими даними.
# 4.1. Машинне навчання та штучний інтелект
Машинне навчання та штучний інтелект забезпечують автоматизацію процесів аналізу медіа-контенту. Це дозволяє не тільки прискорити обробку даних, але й покращити якість аналізу завдяки точності моделей, що навчаються на великих масивах даних. Наприклад, алгоритми класифікації можуть автоматично сортувати медіа-контент за темами, а методи кластеризації групувати схожі за змістом тексти, що дозволяє виявити тренди та закономірності в масивах медіа-даних.

Machine learning and AI [14]
Штучний інтелект також дозволяє будувати предиктивні моделі, які можуть прогнозувати поведінку аудиторії або оцінювати ймовірність розвитку тих чи інших тенденцій у медіа. Наприклад, аналіз соціальних мереж може допомогти передбачити, як новина або подія вплине на громадську думку. Завдяки цьому дослідники та аналітики можуть приймати більш обґрунтовані рішення щодо впливу медіа на суспільство.
# 4.2. Великі дані (Big Data)
Технології великих даних дозволяють працювати з масивними обсягами інформації, яку важко або неможливо обробити традиційними методами. У сфері медіа-аналітики це особливо важливо, оскільки сучасний медіа-простір генерує гігантські обсяги контенту щодня — це тексти, зображення, відео, аудіо, соціальні медіа тощо.

Big Data [5]
Обробка великих даних дозволяє виявляти приховані тенденції, кореляції та закономірності, які важко помітити при ручному аналізі. Використання цих технологій дозволяє швидко отримувати релевантні результати, зокрема оцінювати настрої аудиторії, виявляти тренди та зміни у сприйнятті суспільства. Big Data також відкриває можливості для роботи з мультимедійним контентом, дозволяючи аналізувати не лише тексти, але й зображення та відео, що розширює можливості медіа-аналітики.
Комбінування методів машинного навчання та великих даних забезпечує дослідникам потужний інструмент для аналізу складних і динамічних медіа-екосистем.
# Порівняльна характеристика існуючих засобів вирішення завдання
| Властивості | Semantrum | Neticle Media Intelligence | YouScan |
|---|---|---|---|
| Functionality (Функціональність) | Широкий спектр інструментів для моніторингу та аналізу ЗМІ, підтримка різних типів контенту, включаючи текст, відео та зображення. | Аналіз медіа-контенту в реальному часі, відстеження трендів, виявлення ключових слів і емоцій. | Моніторинг соціальних мереж, визначення настроїв, робота з зображеннями, інтеграція з CRM. |
| Usability (Зручність) | Зручний інтерфейс, легко налаштовувані дашборди, зручна візуалізація даних. | Проста навігація та інтуїтивний інтерфейс, налаштовувані сповіщення та звіти. | Інтуїтивний інтерфейс, прості налаштування для створення звітів і відстеження активності в соцмережах. |
| Reliability (Надійність) | Висока стабільність роботи, підтримка великих обсягів даних, регулярні оновлення. | Забезпечує стабільний доступ до аналітичних даних з можливістю резервного копіювання. | Надійне відстеження та аналіз великих обсягів даних, зокрема з соцмереж. |
| Performance (Продуктивність) | Швидка обробка запитів, можливість роботи з великими обсягами даних. | Швидка обробка результатів моніторингу та виведення звітів. | Підтримка великих обсягів даних, висока швидкість обробки інформації в реальному часі. |
| Supportability (Підтримка) | Підтримка 24/7, доступні оновлення, документація та навчальні матеріали. | Підтримка користувачів через чат і email, регулярні оновлення, навчальні матеріали. | Широкі можливості для інтеграції з іншими системами, підтримка користувачів через різні канали зв'язку. |
# Висновки
Аналіз медіа-контенту є надзвичайно актуальним завданням у сучасному інформаційному суспільстві. З огляду на постійне збільшення обсягів даних і їхню різноплановість, цей процес стає дедалі складнішим, але й більш затребуваним у багатьох сферах.
На основі проведеного аналізу існуючих інструментів і підходів можна дійти наступних висновків:
# 1. Доцільність розробки нової інформаційної системи
Хоча нинішні інструменти аналізу медіа-контенту (такі як Semantrum, Neticle Media Intelligence та YouScan) надають корисні функції, вони часто обмежені у своїй універсальності та здатності обробляти різні типи контенту одночасно. Більшість з них спрямовані на вирішення лише частини завдань, що стосуються тексту, графіки, аудіо або відео окремо.
Необхідність створення нової системи полягає у розробці рішення, що поєднує в собі наступні переваги:
- Універсальність: підтримка аналізу різних типів медіа-контенту, що дозволить зібрати всі дані в одному місці.
- Сучасні технології: використання новітніх технологій обробки природної мови (NLP), машинного навчання та штучного інтелекту для глибшого аналізу та виявлення патернів у контенті.
- Ефективність обробки: застосування підходів великих даних для швидкої обробки великих обсягів інформації, що є критично важливим для своєчасного прийняття рішень.
- Висока точність: нова система повинна забезпечувати вищу точність та релевантність результатів аналізу, завдяки вдосконаленим алгоритмам семантичного аналізу.
# 2. Необхідність інтеграції з сервісами третіх сторін
Оскільки значна частина медіа-контенту створюється і розповсюджується через соціальні мережі та онлайн-платформи, інтеграція з сервісами третіх сторін є критично важливою. Це дозволить отримувати доступ до великого масиву даних і розширювати можливості системи в реальному часі.
Ключові елементи інтеграції включають:
- API: використання існуючих API (соціальних мереж, новинних платформ тощо) для збору та аналізу медіа-контенту з різних джерел, що зменшить час та зусилля на збирання інформації.
- Хмарні технології [15]: інтеграція з хмарними сервісами для забезпечення масштабованості та доступу до потужних обчислювальних ресурсів.
- Партнерство з провайдерами: співпраця з постачальниками послуг обробки природної мови та штучного інтелекту, що дозволить швидко впроваджувати необхідні функції.
# 3. Обмеження модифікації існуючих систем
Хоча модифікація існуючих інструментів може здаватися більш економічно вигідною, вона має значні обмеження. Багато з цих систем були створені для вирішення вузько спрямованих завдань і не підтримують сучасні технології чи типи даних, які потребують інтеграції.
Нова інформаційна система, яка буде спроектована з урахуванням сучасних викликів і можливостей, матиме переваги, такі як більша гнучкість, ширший функціонал і можливість роботи з різноманітними типами контенту.
# 4. Вплив на бізнес і аналітику
Розробка нової системи стане вирішальним кроком для компаній, які прагнуть отримувати максимально релевантні та актуальні інсайти з медіа-контенту. Вона дозволить значно покращити процес прийняття рішень на основі даних, підвищить ефективність маркетингових кампаній та забезпечить глибокий аналіз взаємодії користувачів з контентом і брендами.
Таким чином, створення нової системи для інтелектуального аналізу медіа-контенту є не лише доцільним, але й необхідним кроком для забезпечення конкурентоспроможності на ринку, де доступ до інформації відіграє ключову роль у бізнесі та прийнятті рішень.
# Посилання
- Медіа-контент
- Обробка природної мови
- Інтелектуальний аналіз тексту
- Токенізація
- Великі дані
- Метадані
- Інформаційний шум
- Моніторинг
- API
- Семантичний аналіз
- Аналіз тексту
- Токенізація
- Комбіновані підходи
- Машинне навчання та штучний інтелект
- Хмарні технології (Сloud Technology)
- Semantrum
- Neticle Media Intelligence
- YouScan